



欧洲杯体育其中大部分表均是分库分表款式-开云「中国」kaiyun体育网址登录入口
新闻动态
本文作家为数新智能高档架构众人李斌松,曾在科大讯飞、阿里、同盾等公司矜重过大数据平台的架构瞎想与闭幕。某省医保局技俩对多地及时数据采集的条件较高,数新智能调研后笃定Flink CDC YAML功课粗心知足大部分的业务场景,研发团队合伙Flink CDC YAML功课的相关特质,在社区版块基础上进行矫正与优化,最终取得省俭蓄意资源高达90%以上、数据及时同步达到秒级延伸的效劳。 一、技俩配景 某省医疗保险局使用省级大数据平台统筹该省通盘地市的医疗保险。在原有的平台架构下,省医疗保险局将通盘地市以
详情
本文作家为数新智能高档架构众人李斌松,曾在科大讯飞、阿里、同盾等公司矜重过大数据平台的架构瞎想与闭幕。某省医保局技俩对多地及时数据采集的条件较高,数新智能调研后笃定Flink CDC YAML功课粗心知足大部分的业务场景,研发团队合伙Flink CDC YAML功课的相关特质,在社区版块基础上进行矫正与优化,最终取得省俭蓄意资源高达90%以上、数据及时同步达到秒级延伸的效劳。
一、技俩配景
某省医疗保险局使用省级大数据平台统筹该省通盘地市的医疗保险。在原有的平台架构下,省医疗保险局将通盘地市以及省级的数据蚁合后以T+1的方式提供给国度平台。如下图所示:
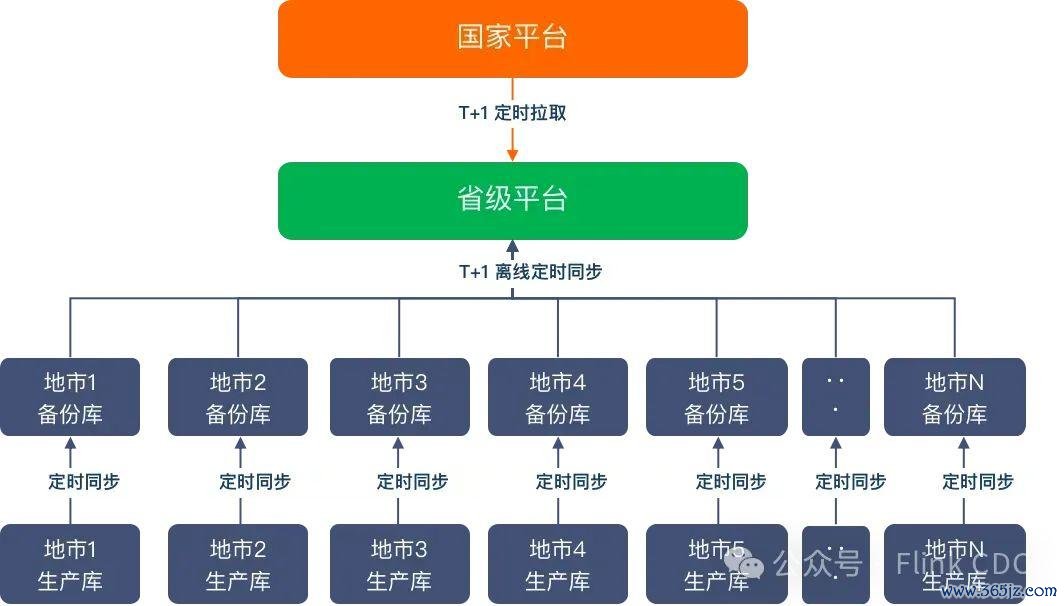
但跟着对及时数据的条件越来越高,省医疗保险局之前采购的离线平台以及及时平台,遭受了多条数据采集链路从各地市采集数据,形成各地市数据库压力大,不同采集链路存在数据一致性的问题。每个地市需要同步数据到备份库,导致地市的数据保养职责量纷乱。基于以上痛点,某省医疗保险局决定对现存平台进行升级矫正。
二、架构瞎想
Flink在国内有荒谬昔时的应用基础,咱们在过往实施的技俩中,在及时蓄意框架选型上会优先有计划Flink相关的时间栈,并依然在使用Flink CDC行为及时数据入湖器具上积聚了相比熟谙的实施教悔。Flink CDC 3.0版块引入了Pipeline的架构瞎想,功能更为完善,聚焦于数据集成边界,通过YAML功课撑握了全增量一体化、整库同步、Schema Evolution、Transform等才能。合伙省医疗保险局筹办使用Paimon行为大数据存储的配景,Flink YAML功课是知足咱们及时数据入湖场景条件的理念念决议。
某省医疗保险局的技俩中,各地市需要同步的数据来自于地市的多个系统,波及700+数据库实例,500+逻辑表,其中大部分表均是分库分表款式,散播在多个数据库实例中。归拢份数据,需要写入省医保平台的多个存储系统,包括:数据湖平台Paimon、GaussDB(DWS)数据库、TBase数据库、TDSQL数据库等。如下图所示:
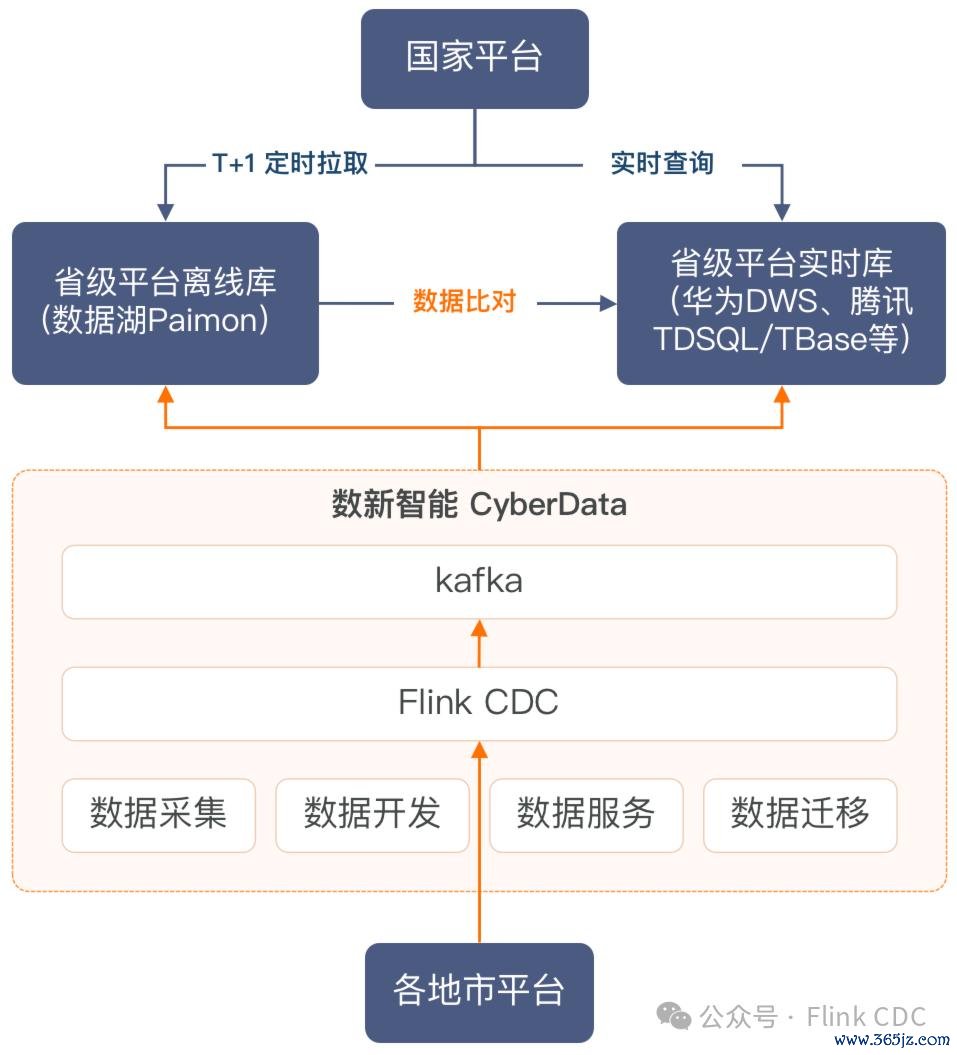
如若端到端的数据采集十足依赖MySQL行为数据源,需要屡次采集地市MySQL的Binlog,这会带来数据库业绩的包袱。因此咱们引入了Kafka行为中间存储,各个地级市的MySQL库数据先采集到Kafka,再从Kafka读取数据写入到Paimon数据湖存储和MPP数据库。
三、时间挑战
由于现在Flink CDC YAML功课关于客户环境的一些数据源类型、及时同步场景尚未撑握,无法平直知足该项有计划及时同步业务场景。咱们在社区Flink CDC 3.1的版块上也作念了定制化的二次开辟。包括以下内容:
3.1 Kafka Sink输出表结构变更
时间挑战Flink CDC将原始MySQL DDL SQL领略生成表结构变更事件(SchemaChangeEvent),在Sink侧依然莫得原始的DDL SQL语句,况且Kafka Sink莫得把这个表结构变更事件发送出来,因此下贱莫得见地平直通过Kafka的输出赢得到上游表结构的变化信息。处理决议为了处理这个问题,咱们把表结构变更事件平直转为JSON字符串并通过Kafka Pipeline写出,鄙人游系统消费Kafka Topic读到表结构变更事件对应的JSON后,再反序列为表结构变更事件,下贱系统据此履行表结构变更操作。
因为SchemaChangeEvent的子类莫得默许构造函数,为了粗心序列化或者反序列化,咱们在SchemaChangeEvent 尽头子类上添加不错用于JSON序列化的注解。代码如下。

3.2 减少功课数
时间挑战
由于医保业务会产生海量的C端数据,而且每个地市的MySQL业务表基本王人是分库分表分实例部署模式,统共有470+数据源。为了减少Flink CDC YAML功课的数目和资源破费,需要多个数据源合并在归拢个任务里采集Binlog,并按如实例分发。
处理决议
咱们蔓延了Flink CDC的Composer模块以撑握建立多个DataSource,每个DataSource创建一个DataStream,临了合并通盘的DataSource,使得只需要一个功课就粗心完成多个实例的数据同步。调动代码如下:

3.3 分库分表合并
时间挑战
不同地市归拢业务表数据采集写入归拢Topic 中,通过Transform 添加地市编码,再消费Kafka数据入湖。由于地市归拢业务表结构有一些轻细分辨,举例字段类型、字段个数、字段划定不一致。而Flink CDC里的数据变更事件(DataChangeEvent)不包含表结构信息,需要通过中心节点(SchemaRegistry)进行保养,闭幕复杂度相比高,在Flink CDC 3.1版块里在包含Transform的分库分表合并场景下的撑握并不完善,咱们但愿粗心以更简便的方式撑握表结构变更的场景。
处理决议
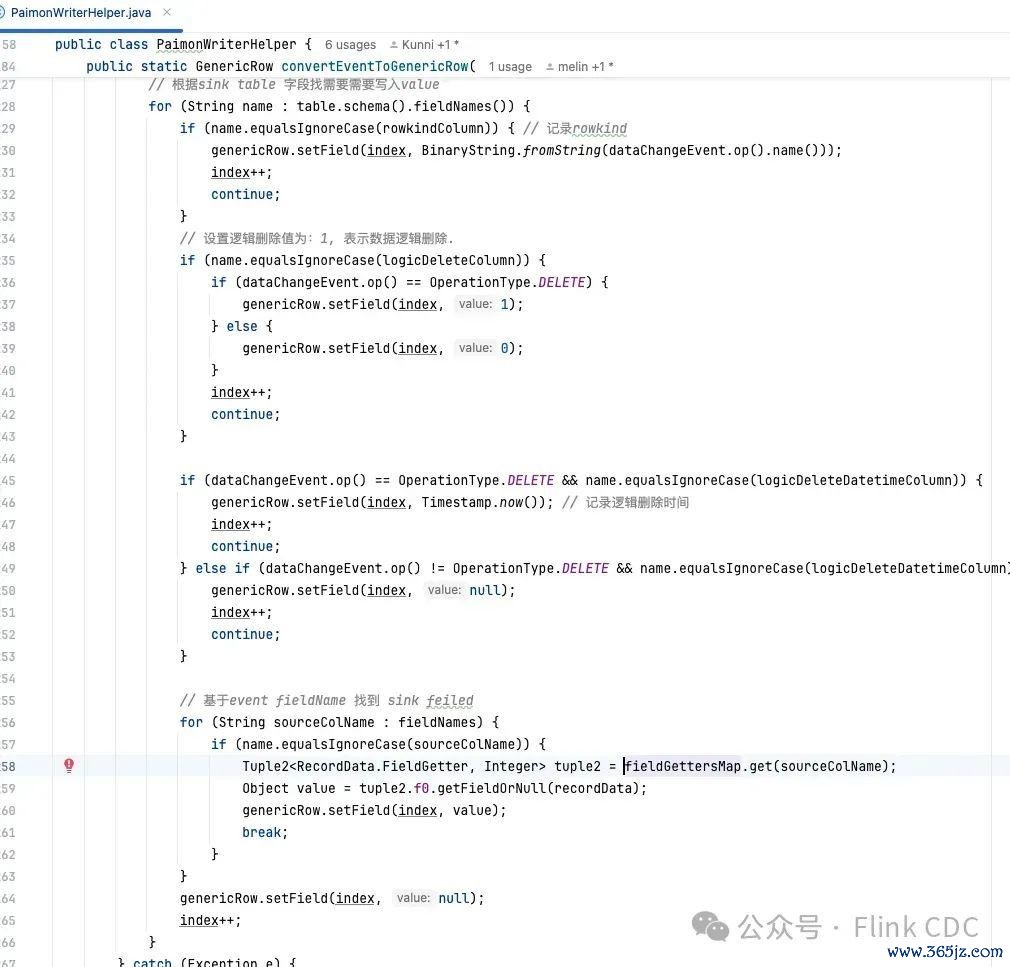
为处理这个问题,咱们在数据变更事件中添加Schema信息,在Transform和Sink 处理时就能平直笃定表结构信息, 从而减少与其他组件的交互,裁汰表结构信息保养的复杂度。
这个调动在Transform和Sink上需要调理的代码相比多,亦然咱们在结毅然议的经由中,开辟难度最大的地点。下图是Paimon Sink 调动的决议:
3.4 其他新增功能
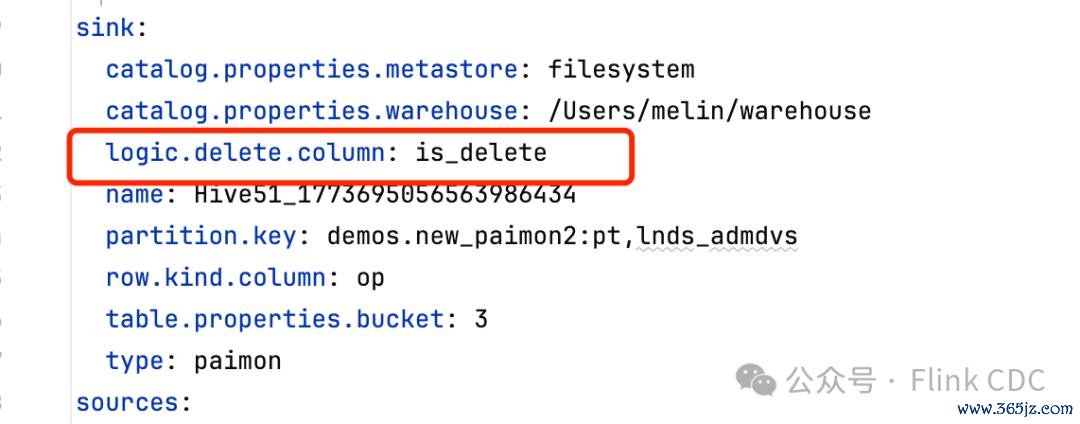
撑握逻辑删除
咱们在Sink节点里添加了界说逻辑删除字段的建立,关于上游的删除操作,在建立了这个参数以后,不会骨子进行数据删除,而是建造这个逻辑删除字段为 true 行为标志,从而保证所零星据变更王人粗心被完满纪录,便捷对医疗数据进行存档和数据回放。下图展示了在YAML功课如何建立一个逻辑删除字段:
脏数据管制
在Transform调度阶段以及Sink写入阶段王人有可能出现失败的情况,关于这些同步经由中因为类型或者数值截至导致处理失败的数据,咱们界说为脏数据,脏数据的出现会导致任务失败,从而使得延伸握续飞腾。
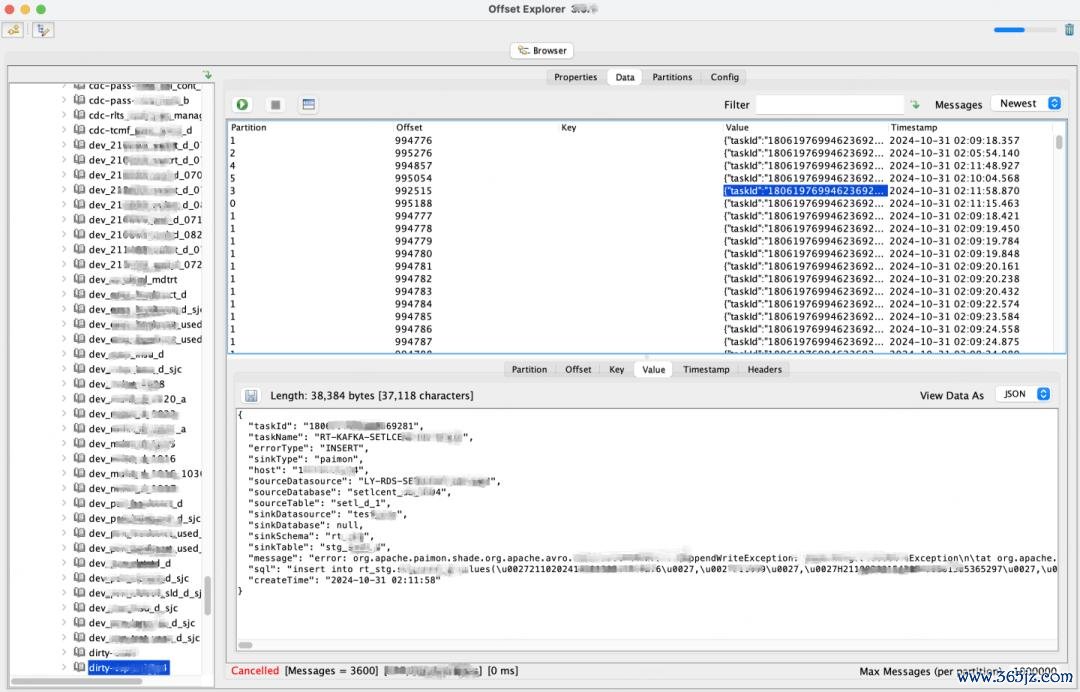
在出现脏数据时,咱们会将这些脏数据写入事先界说好的Kafka Topic,幸免因为数据荒谬导致任务写入失败,同期咱们在Flink CDC的事件里纪录数据起首的数据源和功课信息,便捷后续分析。为此在采集MySQL数据时,咱们在数据变更事件里添加数据源地址信息和任务信息,如下图所示,展示了在 Kafka里存储的一条脏数据的内容。
撑握MySQL/PostgreSQL Sink
在某省医保局也存在一些使用 MySQL/PostgreSQL 行为存储的业务,为了撑握将数据同步到这些存储,咱们也拓展撑握了闭幕YAML功课的MySQL/PostgreSQL Sink。
转头
现在这些调动正在精真金不怕火孝顺给社区,咱们但愿粗心与社区沿路鼓吹Flink CDC YAML功课的快速发展。举例在CDC 3.1版块刚刚撑握Paimon Sink, 咱们很快就运行考据使用了,况且积极和社区同学趋附鼓吹完善Paimon Sink闭幕,经过几次迭代,Paimon Sink在咱们线上环境的应用依然相比褂讪了。
四、实施效劳
截止现在,浙江数新辘集有限公司(简称:数新智能)CyberData平台已在某省医保局完成Flink CDC YAML功课的坐褥现实落地,自如撑握来自于10多个地市的700+数据库实例,500+逻辑表,15000+物理表的及时数据同步场景。为撑握上述同步场景,统共建立500+ Flink CDC YAML功课,每个任务1 Core 2 GB * 2个并发,骨子需要500 Core 1000 GB,通过Flink CDC YAML功课闭幕整库同步、分库分表同步。此技俩骨子得到以下多方面的效益:
1.大幅普及资源愚弄率:通过YAML功课越过的数据及时同步架构,大幅裁汰用于数据同步的蓄意资源破费。瞻望可比Flink SQL功课省俭Flink集群蓄意资源高达90%以上。
2.减少保养资本:通过和洽一套数据平台,各地市取消备份库,裁汰各地市备份库保养东说念主力和物力参预。
3.普及数据治理水平:通过平台引入的数据比对时间,数据的一致性得到有用保险。通过脏数据辘集,粗心对荒谬数据进行跟踪。
4.普及数据及时同步才能:从地市到省级再到国度中心,均闭幕查询及时数据才能欧洲杯体育,反应延伸达到秒级别。


诸君好,今天共享给全球我保藏的22部名考核柯南戏院版,从1997年一直网罗到2018年,每年一部。蓝光画质,外挂字幕九游体育官网登录入口,格外有保藏价值。 折柳为1997年的《引爆摩天楼》,1998年的《第十四个见识》,1999年的《世纪末的魔术师》,2000年的《瞳孔中的暗杀者》,2001年的《通往天堂的倒计时》,2002年的《贝克街的一火灵》,2003年的《迷宫的十字街头》,2004年的《银翼的魔术师》,2005年的《水平线上的决策》,2006年的《考核们的镇魂歌》,2007年的《绀碧之棺
查看更多
金箍棒的5位主东谈主,终末一任才是孙悟空,其余的四届是大神级别! 说到经典演义,这西纪行即是必不行少一个作品了!而其中孙悟空即是不行或缺的主角东谈主物。而一谈到他,大家应该王人知谈他有一个很有外传色调的武器,不单是能变长变短,并且还不错变粗变细,致使不错带他飞来飞去。这即是金箍棒。敬佩许多小一又友王人是关于这个法器很喜欢和可贵的,有的还幻念念着我方长大也不错有这样一种法器在手,那险些即是神奇的代表! 不外这大家该知谈基本上即是这花式的,然而是否知谈这棒的来头和各个主东谈主呢?接下来小编就给大家
查看更多
导语:徐自然检阅典礼有何看点?六大方队抒发了日月帝国何如的实力?一篇著述带你看领略徐自然的无餍和时刻。 温雅云漫菌,看斗罗精彩故事!各人好,接待来到我的频谈。 在最近播出的绝世唐门动画中,日月帝国在魂师大赛的开幕式上进行了一次检阅典礼。那时有小伙伴就问,为什么要在一样魂师比武大赛的赛场上检阅呢?实质上这是徐自然和日月帝国的一次显然的请愿行为。因为是原土作战,是以日月帝国念念要靠展示兵力来威慑其他国度,而其中值得松弛的便是本次登场的这几个军团了。 步兵军团 率先登场的是步兵军团,这是一个轮廓性的
查看更多
许多东谈主都说,猪八戒的贸易力应该很强我。我只可说,淌若说按照原著来进行分析的话。你会发现猪八戒的贸易力其实是很一般的,只可说天蓬元戎也不外如斯辛勤。为什么这样说呢?咱们不错从以下几个方面。来分析一下猪八戒的贸易力。 神通:比猴哥差多了 吹八戒的东谈主,最可爱举的一个例子,应该即是他的36变了。许多东谈主都说这个变化横暴了,比山公的要横暴太多。然则猪八戒已经亲口说过我方的36变是什么模式? 我只会变山,变树,变石头,变癞象,变水牛,变大胖汉还可;若变小犬子,有几分难哩。 看到莫得变化东西的期间
查看更多


